
Introduction
Cloud-based generative AI promised a simple deal: access frontier models via API, pay only for what you use, and skip the infrastructure headache. For proof-of-concept work, that deal held up. For production deployments at scale, the economics and control trade-offs tell a different story.
Across logistics, healthcare, financial services, and field operations, enterprises are pulling AI workloads back behind their own firewalls. Dell's 2024 research found that 82% of global IT decision-makers prefer to build, train, or use GenAI models on-premises or through hybrid infrastructure — a clear signal that cloud-first GenAI strategies need a harder look.
Cloud-only GenAI hits real limits when operational data is sensitive, transaction volumes are high, or latency can't be negotiated away. This post covers the business and compliance pressures driving the shift on-premises, how to assess whether your organization has crossed that threshold, and what a practical transition looks like.
Key Takeaways
- 82% of IT decision-makers prefer on-premises or hybrid GenAI infrastructure, per Dell's 2024 research
- Cloud GenAI costs stay manageable during pilots, but per-token pricing breaks down fast at enterprise volume
- GDPR, HIPAA, DORA, and data sovereignty laws impose compliance constraints that cloud providers alone can't meet
- Open-source LLMs — LLaMA, Mistral, Mixtral — have closed the performance gap enough to make on-premises deployment a real option
- The more useful question: which workloads have already outgrown cloud-only deployment
Why Enterprises Are Moving Away from Cloud-Only GenAI
The Proof-of-Concept Trap
Cloud GenAI is an easy starting point. No upfront hardware costs, no deployment complexity, and API access to capable models within hours. Most enterprises began there, and for early experimentation, it worked.
The problem surfaces when GenAI moves from sandboxed demos into live workflows — customer support automation, logistics planning, document processing, risk analysis. Every query sent to a third-party API now carries real operational data. That's when data governance teams, legal, and the board start asking about data residency, contractual liability, and what providers actually do with query logs.
IBM's 2024 research found that 57% of IT professionals cite data privacy as the primary barrier to GenAI adoption. Data sent to cloud-hosted LLMs may be logged, retained, or used in model improvement — terms that vary by provider and change over time.
The Cost Problem at Scale
Cloud pricing looks reasonable at low volume. It stops looking reasonable when you multiply per-token costs across hundreds of thousands of daily interactions.
Current pricing from major providers gives a sense of the exposure:
| Provider | Input (per 1M tokens) | Output (per 1M tokens) |
|---|---|---|
| OpenAI GPT-5.5 | $5.00 | $30.00 |
| Anthropic Claude Sonnet | $3.00 | $15.00 |
| Azure OpenAI GPT-4o | $2.75 | $11.00 |
| Amazon Bedrock (Claude 3.5) | $6.00 | $30.00 |

Enterprise LLM API spend more than doubled in the first half of 2025, from $3.5B to $8.4B, according to Menlo Ventures. At those volumes, per-call pricing isn't an operating cost — it's a structural risk.
Flexera's 2025 report found that 84% of organizations struggle to manage cloud spend, with budgets exceeding limits by an average of 17%. As GenAI embeds deeper into core systems, that gap compounds.
Vendor Lock-In and the Open-Source Shift
Building production workflows around a single cloud provider's AI services creates dependency that's expensive to undo. Migrating pipelines built on Amazon Bedrock or Azure OpenAI means rearchitecting integrations, retraining teams, and absorbing potential downtime. Those switching costs keep enterprises anchored to providers even when better options exist.
Open-source models have shifted that calculus. Several now benchmark competitively against closed-source alternatives at a fraction of the total cost:
- Llama 3 was pretrained on over 15 trillion tokens and matches frontier model performance on most standard benchmarks
- Mixtral-8x7B outperforms Llama 2 70B across the majority of standard evaluations
- 46% of enterprise respondents said they preferred open-source models heading into 2024 — up sharply from prior years
The perceived advantage of cloud-only frontier models has narrowed. For many workloads, it's gone entirely.
Data Privacy, Compliance, and Sovereignty: The Case for On-Premises
Regulatory Frameworks That Create Hard Requirements
Data privacy concerns aren't just theoretical. Multiple regulatory frameworks impose concrete requirements on where data is processed and who can access it:
- GDPR (Articles 28 and 44): Requires controllers to use only processors with sufficient technical and organizational guarantees; restricts transfers to third countries without meeting specific conditions
- HIPAA: Cloud service providers handling electronic protected health information (ePHI) qualify as business associates — requiring a signed BAA even for encrypted no-view storage
- DORA (financial services): Requires ICT contracts to specify service locations, data storage regions, and audit/access rights for critical functions
- CCPA: Treats precise geolocation as sensitive personal information; consumers can request deletion including from service providers
- SEC Rule 17a-4: Broker-dealer records must maintain audit trails — and outsourcing doesn't relieve broker-dealers of that responsibility

Cloud providers can sign BAAs and DPAs. What they can't always guarantee is where your data actually lands in a multi-region architecture, which log retention policies apply to your queries, or what happens to data processed through shared inference infrastructure.
Intellectual Property Exposure
When enterprises use RAG pipelines or fine-tune models on proprietary datasets through cloud APIs, those datasets leave the organization's perimeter. The growing "fair use" debate around LLM training — and the FTC's warning that it can require deletion of models built with improperly obtained data — has pushed more enterprises to avoid processing proprietary data externally.
Data Sovereignty for Multinationals
Multinational companies may face legal requirements to keep data within specific geographic boundaries. Cloud providers' multi-region architectures can approximate this, but the governance overhead is significant. On-premises or private cloud deployment removes the ambiguity entirely — data stays where you put it.
Auditability is the other half of the equation. When an incident or compliance audit occurs, on-premises deployments give organizations complete visibility into data flows, access logs, and model behavior — without waiting for a third party's disclosure timeline.
The Business Case: Cost, Performance, and Customization at Scale
When On-Premises Becomes Cheaper
The upfront capital cost of on-premises AI infrastructure is real. An 8x NVIDIA H100 server system runs approximately $833,806. But at sustained utilization, the math flips quickly.
Lenovo's 2025 TCO analysis compared that system against AWS EC2 p5.48xlarge at $98.32/hour on-demand, estimating breakeven at around 8,556 hours — roughly 11.9 months. The five-year savings projection: $3.4M versus continuous cloud spend.
The tax treatment adds another layer. On-premises hardware can be capitalized and depreciated:
- Section 179 expensing: Up to $2.5M deducted in the year of purchase (2025)
- Standard depreciation: Computers depreciate over a 5-year schedule
- Cloud SaaS: Classified as operating expenses — no depreciation benefit
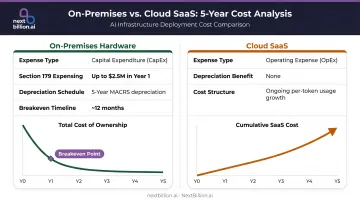
For finance teams modeling multi-year AI budgets, that distinction changes the conversation.
Performance Where It Matters
Latency isn't an abstract concern for real-time operational AI. Fraud detection, dispatch optimization, and predictive routing all require decisions in milliseconds, not seconds. Internet round-trips through shared cloud infrastructure introduce variable latency that isn't acceptable in high-transaction environments.
For logistics and field service specifically, this is a concrete technical constraint. NextBillion.ai's on-premises routing deployment delivers 20x higher throughput and 3x lower latency compared to typical cloud deployments — a difference that matters when you're running real-time dispatch across thousands of active vehicles.
Customization Without Platform Constraints
On-premises deployments give engineering teams direct control over model behavior — something cloud APIs simply don't allow. Organizations can:
- Fine-tune models on proprietary datasets without data leaving the environment
- Modify inference behavior outside provider-controlled update cycles
- Integrate directly with internal databases, bypassing API rate limits
- Build against system interfaces designed for their use case, not a generic one
For enterprises with deeply specialized operational data — route histories, maintenance logs, customer behavior patterns — training on that data in-house means the model learns operational nuances no external provider could replicate. That's a durable edge, not just a compliance checkbox.
Industries Making the Shift — and What's Driving Them
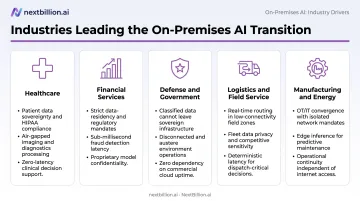
Different industries are hitting the on-premises threshold for different reasons:
Healthcare HIPAA's business associate requirements create compliance complexity around any cloud-hosted AI that touches patient data. Predictable audit trails matter here. Organizations like Mayo Clinic have invested in dedicated on-premises AI computing infrastructure specifically to maintain control over clinical data.
Financial Services DORA, SEC Rule 17a-4, and FINRA's 2024 guidance on AI governance create layered obligations around data location, audit access, and supervision. High transaction volumes also make per-token cloud pricing economically untenable at scale.
Defense and Government Air-gap requirements for classified data effectively mandate on-premises deployment. Palantir and Microsoft's 2024 partnership to deliver AI services in Azure Government Secret and Top Secret environments illustrates how even "cloud" solutions in this sector operate as isolated private infrastructure.
Logistics, Field Service, and Last-Mile Delivery This is where operational sensitivity and real-time latency requirements converge. Route histories, driver location data, customer addresses, and delivery patterns are all competitively sensitive — and increasingly subject to privacy scrutiny:
- CCPA classifies precise geolocation as sensitive personal information
- The FTC has taken enforcement action against companies mishandling location data
- Sub-second latency requirements for dispatch and routing optimization make local inference a technical necessity, not a preference
Manufacturing and Energy Siemens Industrial Copilot for Operations runs on-premises with NVIDIA RTX PRO 6000 Blackwell GPUs — delivering a 30% reduction in reactive maintenance time and 25x acceleration in AI execution for predictive maintenance and quality inspection. Cloud dependency introduces outage risk that's operationally unacceptable on the plant floor.
What Enterprises Should Evaluate Before Going On-Premises
Infrastructure and Operational Readiness
Key questions before committing:
- Do you have GPU-capable hardware, or budget for it? (NVIDIA A100/H100 class for serious inference workloads)
- Do you have a container orchestration platform (Kubernetes) and the team to manage it?
- Can your physical space and power capacity support the hardware requirements?
- Do you have a DevOps or MLOps team with the capacity to maintain the environment?
Gartner estimates that GenAI will require 80% of the engineering workforce to upskill through 2027 — capital alone won't close that skills gap.
Security Certifications and Compliance Posture
On-premises doesn't automatically mean secure. Enterprises should require relevant certifications from any vendor platform used in their deployment:
- SOC 2 Type II — validates security, availability, and confidentiality controls through independent audit
- ISO/IEC 27001 — defines requirements for an information security management system covering confidentiality, integrity, and availability
For logistics and field service enterprises deploying AI-powered routing and location intelligence, NextBillion.ai supports installation within a customer's own Kubernetes environment (AWS EKS, GCP GKE, Azure AKS, or self-managed) and holds both SOC 2 Type II and ISO/IEC 27001:2013 certifications. All routing and location data stays behind the customer's firewall — no external data transmission. This architecture satisfies GDPR/CCPA mandates, data residency requirements, and government procurement rules through technical controls, not just contractual ones.
Deployment Model Fit
Compliance requirements and infrastructure readiness together should inform where workloads run. A practical deployment framework:
- Start with cloud for proof-of-concept and low-sensitivity workloads
- Define thresholds — what volume, compliance requirement, or latency constraint would trigger migration?
- Assess hybrid options — cloud for experimentation and burst capacity, on-premises for production workloads handling sensitive data
- Prioritize by risk — move the most sensitive, highest-volume, or most latency-critical workloads first
Frequently Asked Questions
Can AI be deployed on-premises?
Yes. Large language models and generative AI systems can run entirely within an organization's own infrastructure, using GPU-accelerated servers, a Kubernetes orchestration platform, and an inference engine. Most enterprise-grade vendors now ship production-ready on-premises deployment packages.
What AI tools do big companies use?
Large enterprises typically combine open-source foundation models (LLaMA, Mistral, Mixtral) with platforms like NVIDIA AI Enterprise or IBM Watson for on-premises workloads. Cloud services from OpenAI, Anthropic, and Google handle lower-sensitivity use cases. The trend is toward hybrid stacks that balance control with convenience.
What is the difference between on-premises and cloud generative AI?
On-premises GenAI runs within an organization's own infrastructure — data stays behind its firewall, under its control. Cloud GenAI runs on a third-party provider's servers, accessed via API. The practical differences are data control, compliance flexibility, latency characteristics, customization depth, and cost structure at scale.
Is on-premises AI more expensive than cloud?
On-premises has higher upfront capital costs but lower ongoing costs at sustained utilization. Cloud AI starts cheap and gets expensive as volume grows. Based on Lenovo's 2025 analysis, breakeven against on-demand cloud pricing can occur in under 12 months for heavy workloads, with multi-year savings reaching into the millions.
What infrastructure do you need to run generative AI on-premises?
Core requirements include GPU-capable servers (NVIDIA A100 or H100 class), a Kubernetes orchestration platform, an optimized inference engine, monitoring and observability tooling, and optionally a vector database for RAG pipelines. A DevOps or MLOps team is required to manage and maintain the environment on an ongoing basis.
Which industries benefit most from on-premises generative AI?
The strongest business cases come from industries where data sensitivity, compliance, or latency leave little room for compromise:
- Healthcare — HIPAA compliance requirements restrict data from leaving controlled environments
- Financial services — privacy regulations plus high transaction volumes make on-premises economics compelling
- Defense and government — air-gap requirements make cloud deployment a non-starter
- Logistics and field service — operational data sensitivity combined with real-time latency demands


