


Table of Contents
The ability to provide accurate ETAs (Estimated Time of Arrival) is a crucial component of user experience across industries like ride hailing, field service, food delivery and logistics. Calculating ETAs using traditional methods (route planning + traffic information) and machine learning is very challenging; we won’t be covering that today. Instead, we will discuss one of the fundamentals of good ETAs — quantitatively measuring ETA quality.
Being a traditional estimation problem, there are already some well-known metrics that are designed for measuring ETA accuracy. When it comes to transportation in particular, there are more factors that need to be taken into account. In this article, we’ll begin by exploring the traditional metrics and then talk about our learnings around ETA benchmarking at NextBillion.ai.
Traditional statistical metrics
Let’s look into some traditional estimation metrics that are widely used for ETA measurement.
MAPE: Mean Absolute Percentage Error
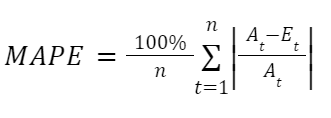
where At is the actual value and Et is the estimated value. A 10% MAPE means that if the Actual Time of Arrival (ATA) is 10 minutes, the original ETA was within the range of 9 – 11 minutes.
Pros and Cons of MAPE
- Pros: MAPE is a normalized number that is comparable among different types of trips and regions. You can directly compare your MAPE metrics in Paris against those in London. It’s also a rather straightforward concept; you can easily understand the meaning of a 10% MAPE.
- Cons: MAPE is too sensitive for short trips. Imagine a very quick trip that just takes a two-minute drive. The ETA for this trip could easily be anywhere from one to three minutes, but that leaves a MAPE of 50%. The impact of this 50% MAPE is equivalent to having a trip with an ETA of two hours that actually take three hours to complete.
A useful tip to use MAPE is to modify the formula to the following:
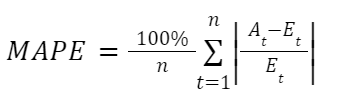
We’ve changed the denominator from the actual value At to the estimated value Et. This makes things simpler from a user experience perspective, as users usually see the ETA first, and only when the trip finally ends do they compare the actual time taken against the original estimation. A modified MAPE of 10% means that if you start with an ETA of 10 minutes, the ATA will be within 9 – 11 minutes.
RMSE: Root-Mean-Square Error
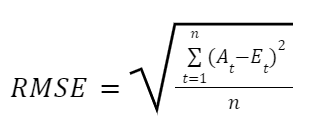
Pros and Cons of RMSE
- Pros: RMSE is dimensionally consistent, making it easy to understand. It essentially weights trips based on duration, instead of just error percentages, which circumvents the issues that MAPE faces with short trips.
- Cons: Similar to how MAPE is sensitive to short trips, RMSE is sensitive to outliers in terms of trip duration; extreme outliers may lead to a poor value. Since RMSE is correlated to the duration of trips, it’s difficult to compare different regions with each other. A normalization needs to be applied.
Both MAPE and RMSE are mathematical metrics that are great for complex calculations and can be used as objective functions in your machine learning algorithms. But can they measure how users feel about ETAs? It’s probably safe to say no. Nobody likes delayed trips, but people are much more tolerant of early arrivals. Also, the same margin of error could have differing impacts in different scenarios. For a short trip of 10 minutes, a 20% margin of error is just two minutes — some people may not even notice it. But in a 10-hour trip, a two-hour delay is hard to miss and can be intolerable. Clearly, these metrics can’t capture the whole picture. So let’s try to incorporate user experiences into our ETA measurements.
Design your own synthetic metrics for ETA experience
ETAs can mean different things to different users across varying scenarios. Proper user research can tell you what would be a reasonable threshold before your user notices an ETA went wrong. Based on the research, we can build a ‘Good Estimation %’ metric like below:
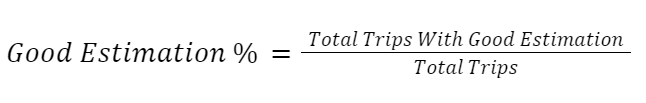
We can define a good estimation as follows:
- For trips shorter than 24 hours, an error within the range of ±2 hours is considered a good estimation
- For trips of 24 to 72 hours, an error of ±6 hours is considered a good estimation
- For trips longer than 72 hours, an error of ±12 hours is considered a good estimation
You can build even more user experience factors into this synthetic metric. For instance:
Define thresholds based on urgency – For all trips during peak hours (7am-10am and 5pm-8pm), errors within 20% are considered good estimations; for all trips during non-peak hours, errors within 40% are considered good estimations.
Define thresholds based on customer type – For trips involving VIP customers, errors within 10% are considered good estimations, whereas the threshold is 20% for all other trips.
This Good Estimation % metric can be much better at showing what your users feel about their ETAs.
On the other hand, you can look into user complaints and find out what a bad estimation looks like. A metric for Bad Estimation % can be introduced in addition to its more positive counterpart, and you can optimize your operations around these metrics.
Find insights from visualization
All the metrics in the world are meaningless if you fail to draw any insights from them. Visualizations are extremely useful for doing just that. Let’s go over a few examples of drawing insights from data visualizations.
An ETA/Distance Error % Graph
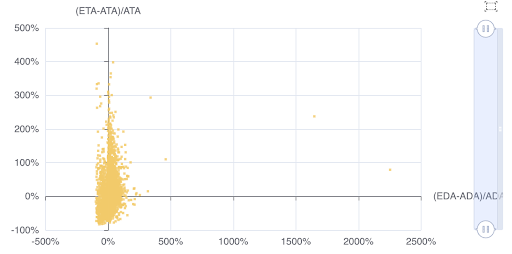
This graph takes into account the distance factors of ETA. It helps us quickly understand if errors are caused by traffic or choice of route. In the above graph, we see an unusual group of samples where the distances are quite consistent, but the ETAs tend to be 200% off the actuals. Therefore, we can conclude that the errors are driven by traffic, and not route choice.
A Box Plot Graph
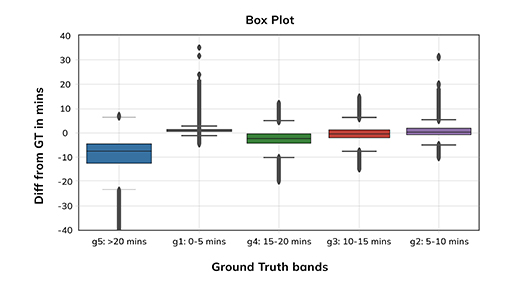
The box plot is a commonly used tool for visualizing the dispersion of data. It displays the minimum, first quartile, median, third quartile and maximum values of the data set. The whiskers extending from the boxes indicate the range of the data, while the individual points beyond the whiskers are outliers in the data. In the above figure, we can easily see that there’s a significant amount of deviation occurring within the 0-5 minute interval, which warrants a deeper look.
A 24-Hours ETA Graph
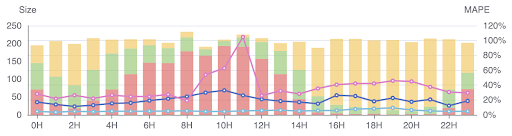
This is a 24-hours graph comparing over-estimated (yellow) vs. good-estimation (green) vs. under-estimated (red) ETAs. By laying the data out in this manner, it becomes obvious that there is a traffic problem. The traffic data being used to generate ETAs in this scenario is probably the average data for each day, which is usually faster than peak-hour traffic and slower than non-peak-hour traffic. This explains the poorly estimated ETAs.
Grouping Trips
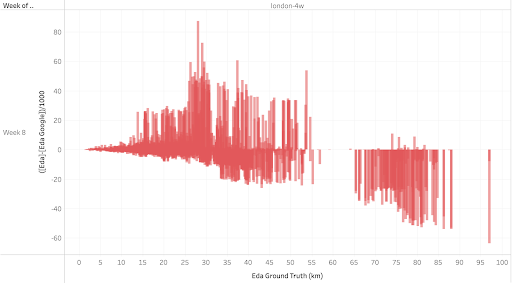
This graph compares the errors of distance estimations with the actual distances. We see a significant group of longer trips showing a trend of underestimation, which is worth investigating. It could lead us to the underlying problem — perhaps a traffic issue, in this case.
Sometimes it’s an art to group your data creatively in such a manner that the truth behind the data reveals itself. In transportation, some useful groupings include:
- Group by length of trips
- Group by intra-city or intercity
- Group by morning-peak, noon, evening-peak, night and midnight
- Group by weekday or weekend
- Group by urban-region or country-region
- Group by vehicle types
- Combinations of the above
It can also be quite useful to look at week-on-week or month-on-month tracks.
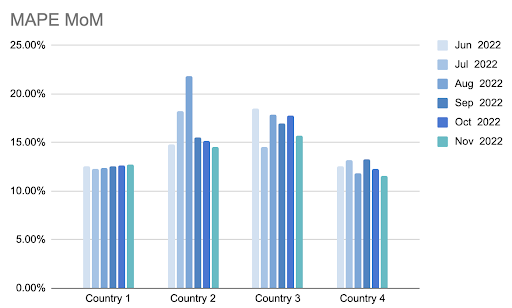
In the above image, we see ETA trends across different countries. Just from a glance, we can tell that in Country 2, traffic patterns became more unpredictable during the vacation season in July and August.
All in all, it’s probably fair to say that benchmarking your ETAs is rarely going to be an easy or effortless process. However, it is your very first step towards generating high-quality ETAs, and thus, an extremely valuable exercise. We hope that this article will help you take that important step with purpose and confidence.
Ready to get started?
Request a DemoTable of Contents
Subscribe to our Newsletters
Get the best practices for route planning & optimization, delivered to your inbox.
Subscribe